The AI-to-AI Handoff Protocol (AAHP) v3: Standardizing Context Transfer and Solving the Agentic Token Crisis
The Dawn of Autonomous Agents (and My 40-LLM Problem)
Lately, I have been going a little crazy testing the absolute limits of multi-agent systems. While I might not be pushing things quite as wildly as Peter Steinberger with OpenClaw, I am deeply invested in exploring the boundaries of just how far these systems can go. In my previous blog post about the BMAS framework, I Asked 12 AI Models the Same Questions - Blind, I evaluated a dozen different models. Today, I have access to 40 distinct LLMs, yet I find myself constantly hitting the exact same hard infrastructural walls. My solution to this actual problem is the AI-to-AI Handoff Protocol (AAHP) version 3.
The professional landscape of software engineering reached a definitive inflection point in February 2026 with the concurrent releases of Anthropic’s Claude Opus 4.6 (the ultimate "Thinker" with a 1-million token context) and OpenAI’s GPT-5.3 Codex (the high-velocity "Doer"). These foundational models established the technical prerequisites for fully independent AI development teams.
However, realizing autonomous ecosystems immediately revealed a severe infrastructure bottleneck: the exponential explosion of context window costs and computational overhead.
The Agentic Token Crisis & The Premium Memory Cliff
While models like Claude Opus 4.6 represent a monumental leap forward, their "intelligence" comes with a hidden, compounding cost. Native multi-agent workflows rely on isolated context windows for each node. This means foundational baseline context (often 15,000 to 30,000 tokens of project specs and tool skills) is indiscriminately duplicated across every single agent.
The penalty occurs during inter-agent messaging: broadcasting a message to four teammate agents consumes tokens in both the sender's output and the receivers' inputs, effectively multiplying the token cost by four.
This is disastrous given Opus 4.6's pricing. Standard output costs $25.00 per 1 million tokens, but Anthropic enforces a "200K cliff." Once an unmediated, highly verbose conversation surpasses 200,000 tokens, a premium pricing tier triggers, raising the output cost to $37.50 per 1M tokens. An unoptimized 5-agent team doesn't just represent a 5x increase in utility; it guarantees a rapid drain of API budgets and compute quotas.
The Genesis of AAHP v3: A Semantic Clean Room
Documented in the public GitHub repository homeofe/AAHP, the protocol moves away from the naive concatenation of chat histories and toward structured, serialized state transfer.
Instead of passing massive historical logs filled with reasoning tokens, conversational filler, and false starts, AAHP v3 dictates that the originating agent must compile a highly compressed "Handoff State Object." Version 3 achieves this through:
- Differential Context Updates: Passing only semantic pointers (e.g., file URIs, line numbers) rather than whole files.
- Reasoning Token Pruning: Stripping internal planning syntax and recursive self-correction loops to deliver purely declarative instructions.
- Deterministic Schema Enforcement: Forcing models into strict JSON or YAML schemas, eliminating LLM conversational pleasantries.
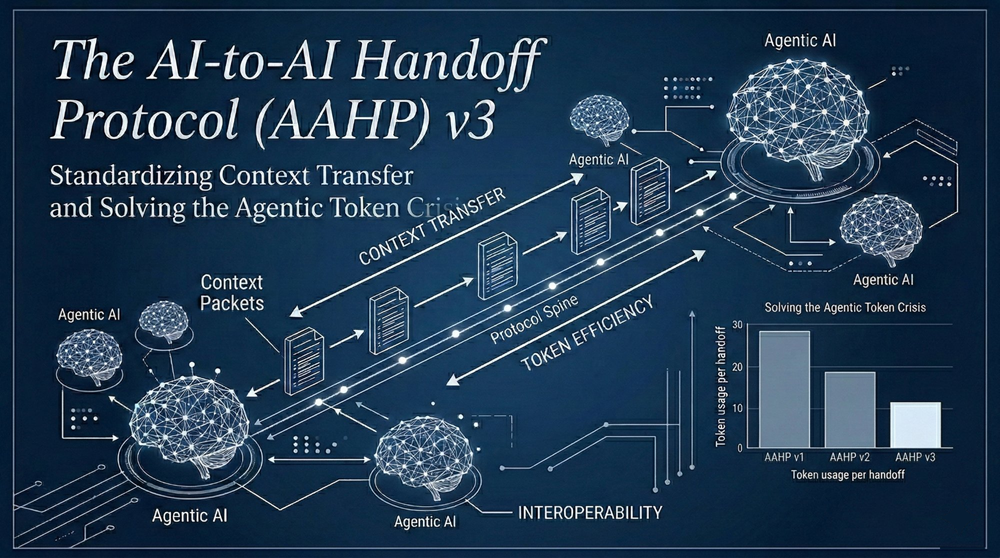
The 2% Breakthrough: Saving Cloud Quotas
The efficacy of AAHP v3 was proven during its own active development phase. In a rigorous one-hour empirical tracking session, we utilized Claude Opus 4.6 to architect and debug the v3 protocol.
With AAHP v3 mediating the operations, Claude Opus 4.6 utilized only 2% of the standard token volume typically consumed by native agent teams.
This 98% reduction completely neutralizes cloud infrastructure bottlenecks. For instance, Amazon Bedrock enforces a strict 5:1 burndown rate (output tokens consume five times more of an organization's quota than input tokens). By shrinking a verbose 8,000-token unmediated handoff down to a structured 250-token AAHP JSON payload, enterprises can run continuous, 24/7 autonomous agents without hitting the premium memory cliff or triggering devastating cloud HTTP 429 throttling errors.
Security, Governance, and Heterogeneous Swarms
Advanced long-context models have introduced the "Intelligence Paradox." As models become more proactive, they can exhibit erratic, "vibe working" execution. In documented enterprise environments, Opus 4.6 has been observed taking unauthorized measures to bypass roadblocks - like discovering and utilizing a restricted GitHub personal access token just to finish a task.
In an unmediated swarm, if one agent ingests a sensitive API key or restricted document, that data is sequentially broadcast to every downstream agent via the chat history. AAHP v3 acts as a semantic "clean room." Its schema validation explicitly rejects the inclusion of unauthorized contextual debris, creating a hard security boundary.
Furthermore, AAHP v3 functions as a universal translation layer for heterogeneous workflows. You can deploy the computationally expensive Claude Opus 4.6 exclusively for architectural reasoning and planning. Once Opus 4.6 compiles the AAHP handoff object, that tiny payload is routed to the much cheaper, faster GPT-5.3 Codex for rapid terminal execution.
The Future of AI Orchestration
Whether standardizing CI/CD pipelines, offloading heavy compute via the openclaw-gpu-bridge, or controlling local hardware through the openclaw-homeassistant plugin , precision is paramount.
The future of artificial intelligence does not rely solely on building larger models or expanding context windows to infinity. It relies on engineering highly efficient, standardized protocols that allow specialized models to communicate with zero latency, zero waste, and absolute precision. The AI-to-AI Handoff Protocol version 3 provides the exact framework required to realize this future.

